enarx (WASM TEE)
2022-02-17 · 13 min read
site: https://enarx.dev
TEE #
Trusted Execution Environments (TEEs) allow organizations to run applications within a set of memory pages that are encrypted with a secret key by the host CPU in such a way that these pages are not accessible to the operating system or any other software, even running at the highest privilege level.
There are currently two leading models of TEEs:
- Process-based: current implementations include Intel’s SGX (Software Guard eXtensions).
- VM-based: current implementations include AMD’s SEV (Secure Encrypted Virtualization).
Applications that need to run in a TEE must be developed specifically for each platform, and they differ significantly depending if it’s a process-based or VM-based TEE model. Additionally, they must implement something called attestation, which is a validation process for the TEE to prove that it’s genuine before it can be trusted by the application. Rewriting the application or the custom VMM that runs it, as well as the attestation, for each hardware platform is extremely complex and time-consuming.
In the next section, we will introduce Enarx, an open source framework for running applications in TEEs that addresses many of the issues raised. We’ll give a simplified overview of the component architecture of Enarx (and how it allows for support for multiple hardware platforms) and the process of creating and deploying applications to TEE instances using Enarx.
Enarx #
Enarx is a framework for running applications in TEE instances – which we refer to as “Keeps”–without the need to trust lots of dependencies, without the need to rewrite the application, and without the need to implement attestation separately.
Enarx aims to minimize the trust relationships required when executing applications, meaning that the only components which need to be trusted are: the CPU and associated firmware, the workload itself, and the Enarx middleware, which is fully open source and auditable. Applications run without any of the layers in the stack (e.g. hypervisor, kernel, user-space) being able to look into or alter the Keep or its contents.
It provides a WebAssembly runtime, based on wasmtime, offering developers a wide range of language choices for implementation, including Rust, C, C++, C#, Go, Java, Python and Haskell. It is designed to work across silicon architectures transparently to the user so that the application can run equally simple on Intel platforms (SGX or the recently-announced TDX), AMD platforms (SEV) or forthcoming platforms such as Arms’ Realms and IBM’s PEF - all without having to recompile the application code.
Enarx is CPU-architecture independent, enabling the same application code to be deployed across multiple targets, abstracting issues such as cross-compilation and differing attestation mechanisms between hardware vendors.
Enarx provides attestation, packaging and provisioning of the application to take place in a way which is transparent to the user. Every instance of an application goes through three steps:
- Attestation: Enarx checks that the host to which you’re planning to deploy is a genuine TEE instance.
- Packaging: Once the attestation is complete and the TEE instance verified, the Enarx management component encrypts the application and any required data.
- Provisioning: Enarx then sends the application and data along to the host for execution in the Enarx Keep.
At no point is the host system able to look inside or change the code or data within a Keep. Thus, Enarx allows organizations with sensitive code or data to run their applications with strong integrity and confidentiality protections.
Components #
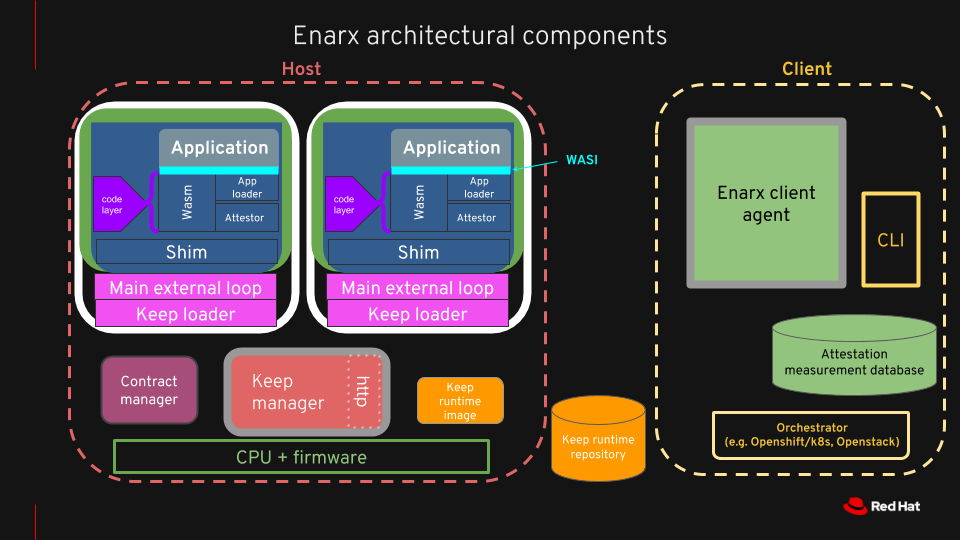
Threat Model #

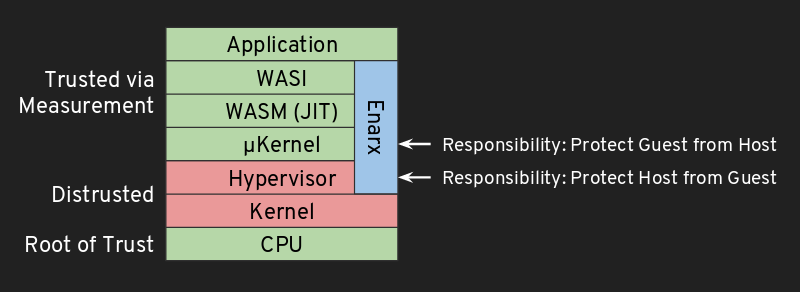
Enarx provides four layers in the run-time stack. Working from the lowest up, they are:
- a VMM (Virtual Memory Manager)
- a microkernel (μkernel)
- a WASM runtime (WebAssembly)
- a WASI implementation (WebAssembly System Interface).
Attestation #
An application which is going to run in an Enarx Keep needs to attest two things:
- The hardware TEE providing Keeps.
- A measurement of the Enarx runtime. This means that Red Hat may need to launch a service to abstract attestation. The way that this works is that the client requests attestation from Enarx. Enarx supplies a blob. The client forwards this to Red Hat. Red Hat will then complete attestation of the h/w environment and translate the measurements of Enarx into a something which allows you to identify the specific version of Enarx.
(??? what is Red Hat in this case? the abstract cloud provider? is "requests from Enarx" like request from a local library, or actually hitting an API??)
From the client’s point of view, the attestation steps of Enarx end up with the following two cryptographically validated assertions:
- The TEE type and version;
- The Enarx version and integrity. The attestation processes associated with the various hardware architectures are very different (see SEV architectural and SGX architectural): providing a common mechanism to abstract this is expected to be a major part of the work associated with this project.
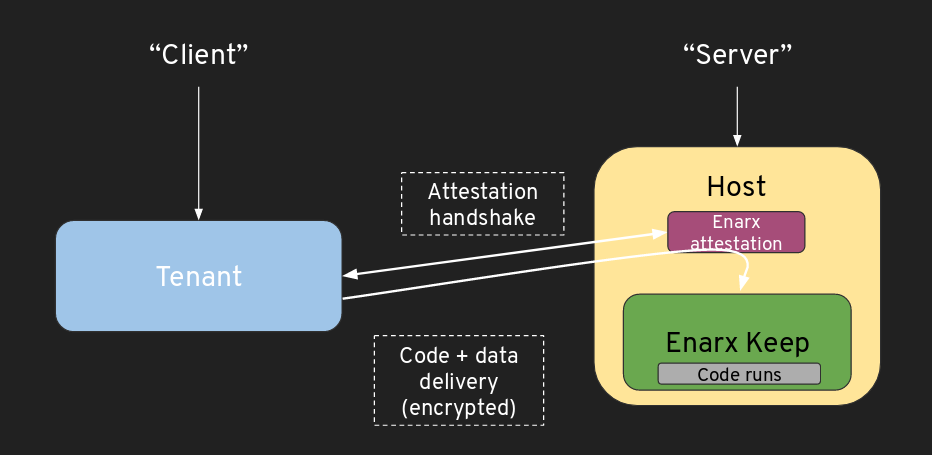
AMD SEV Remote Attestation Protocol #
Goal #
This protocol allows a tenant to:
- Verify the platform certificate chain belonging to the remote host where the Enarx Keep is constructed
- Establish a secure channel with the remote CPU AMD Secure Processor (AMD SP) on the remote host
- Compare its own measurement of the guest's initial state with the AMD SP's measurement from the untrusted host
- Safely deliver its workload to the AMD SP
This protocol maps the regular SEV launch procedure onto a simple client-server model (client sends request to server; server sends its response to client). In fact, the message formats are comprised of data structures defined in the AMD SEV specification.
It is a short, serialized exchange. More importantly, however, it is meant to be an “atomic” transaction. What this means is that the client and the backend complete attestation successfully in this exchange or they don’t. There are no “in-between” end conditions. Therefore, neither party should have any expectation of “retrying” a previous step. It is always forward progress or none at all. As the orchestrator, it is the Keep Manager’s responsibility to know if the keep becomes defunct during attestation, launch, or normal operation. It is expected that the Keep Manager will inform the client of an appropriate error condition and tear down the defunct Keep if necessary.
Message Formats #
The data structures defined in the SEV specification form the substrate for this protocol. As a result, message payloads are binary structures. The messages for this protocol are CBOR-encoded. They will be represented here in Concise Data Definition Language (CDDL).
message = {
certificate-chain-naples //
certificate-chain-rome //
launch-start //
measurement //
secret //
finish
}
certificate-chain-naples = (
"ark": certificate-ca-small,
"ask": certificate-ca-small,
"pdh": certificate-sev,
"pek": certificate-sev,
"oca": certificate-sev,
"cek": certificate-sev,
)
certificate-chain-rome = (
"ark": certificate-ca-large,
"ask": certificate-ca-large,
"pdh": certificate-sev,
"pek": certificate-sev,
"oca": certificate-sev,
"cek": certificate-sev,
)
launch-start = (
"policy": policy,
"pdh": certificate-sev,
"session": session,
)
measurement = (
"build": build,
"measurement": bytes .size 32,
"nonce": bytes .size 16,
)
secret = (
"header": {
"iv": bytes .size 16,
"mac": bytes .size 32,
},
"ciphertext": bytes,
)
finish = /* TODO */
version = (
"major": uint .size 1,
"minor": uint .size 1,
)
build = (
"version": version,
"build": uint .size 1,
)
policy = (
"flags": uint .size 2,
"minfw": version,
)
session = (
"nonce": bytes .size 16,
"wrap_tk": bytes .size 32,
"wrap_iv": bytes .size 16,
"wrap_mac": bytes .size 32,
"policy_mac": bytes .size 32,
)Sequence Diagram #

Syscall Proxy #
Enarx needs to support Keeps that are built on encrypted virtual machine technologies such as AMD SEV and IBM Power PEF. This means that we need to boot an operating system inside the guest VM. However, existing operating systems do not meet the Enarx design principles (especially: minimal trusted computing base [TCB], external network stack and memory safety). Therefore, this page outlines a plan for building a minimal OS which intends to service only the minimal requirements to run Enarx.
Existing Systems #
A traditional virtualization stack (such as Qemu + Linux) is typically composed of four components:
- The Virtual Machine Manager (e.g. Qemu)
- The VM BIOS / Firmware (e.g. OVMF)
- The Guest Bootloader
- The Guest Kernel
The Plan #
In order to remove these problems, Enarx plans to produce three components when running in a VM-based TEE:
- The Enarx VMM
- The Enarx μKernel
- The Enarx Userspace WASM / WASI Runtime
These three components will be tightly coupled and shipped as an integrated system. The interfaces between the components will be considered an internal implementation detail that can be changed at any time. Enarx tenants will validate the cryptographic measurement of the three components (VMM Guest Memory Setup, μKernel and Userspace Runtime) as a single unit to reduce combinatorial complexity.

In order to keep the TCB small, especially the exclusion of a full network stack, we intend to proxy syscalls to the host. This allows us to use as many of the host resources as possible while maintaining a small Keep size. It also allows for performance optimizations as Enarx gets more mature. The above chart shows a full trace of a single syscall across the various components. This works as follows:
-
An Enarx application, compiled to WebAssembly, makes a WASI call, for example:
read(). This causes a transition from the JIT-compiled code into our guest userspace Rust code. This does not entail a full context switch and should be fast. -
The hand-crafted Rust code should translate the WASI call into a Linux
read()syscall. From here we leave Ring 3 (onx86; other architectures have similar structures) and jump into the μKernel, performing a context switch. At this point, some syscalls will be handled internally by the μKernel, for example, memory allocation where the virtual machine has sufficiently allocated pages to handle the request immediately. -
All syscalls which cannot be handled internally by the μKernel must be passed to the host, so the guest μKernel passes the syscall request to the host (Linux) kernel. As an optimization, some syscalls may be handled by the host (Linux) kernel directly. For example,
read()of a socket can be handled immediately by the host kernel, avoiding future context switches. This requires the (future) development of a Linux kernel module to handle these request directly in the host kernel. Since this is an optimization step, we can wait until the interfaces have settled before pursuing this. -
All syscalls which cannot be handled internally by the host kernel must cause a
vmexitin the host VMM. For example, a request for additional pages to be mapped into the guest must be passed to the VMM since that is the component which manages the allocated pages. Like previous layers, any syscalls which can be handled directly in the VMM (for example allocation from a pre-allocated memory pool) should be handled immediately to avoid future context switches. -
In some cases, the VMM will have to re-enter the host kernel in order to fulfil the request. This is the slowest performance path and should be avoided wherever possible.
Syscall Categories and their Layers #
-
Memory Allocation: Memory allocation syscalls should be served by the μKernel from pre-allocated pools of huge pages. Allocation of huge pages should be passed through to the host layers.
-
Networking: All networking syscalls should be passed to the host layers. This ensures that the network stack lives outside the TCB.
-
Filesystem: The guest μKernel should implement a filesystem on top of block encryption and authentication. Block IO should be passed to the host layers. It may even be possible to implement this functionality directly in userspace to reduce the number of context switches. Block authentication, block encryption and the filesystem should be implemented as reusable crates for use in other (non-VM-based keep) contexts.
-
Threading: Techniques like NUMA are extremely hard to implement. Therefore, the μKernel should pass this to the host layers where possible. One particular strategy to accomplish this is to perform vCPU hotplug. When a new thread is created in the guest userspace, a new vCPU is created by the VMM. Therefore there is always a 1:1 mapping between userspace threads and vCPUs. The guest μKernel can pool pre-allocated vCPUs to increase performance.
FAQ #
Why not do containers? #
Would it be possible to implement containers within TEEs? That depends somewhat on the TEE implementation, but the answer is a "kind of yes". However, when you run containers on a host, the interactions that the container runtime has with the host leak all sorts of information that we really don't want to be making available to it. One of the design goals of Enarx is to reduce the number of layers that you need to trust, so this isn't a great fit. We know that containers are great, and one of the interesting sets of questions around Enarx revolves around exactly how you orchestrate Keeps, but whatever that looks like, we won't be doing something which meets the specification for containers, for the reasons outlined above.
(wish they were a bit more specific about this)
Will Enarx offer protection against side-channel attacks? #
The short answer is yes, where possible. To expand on this, first of all this is only a goal for now, as we won't be focusing our efforts on it immediately given we are still working on core functionality. Secondly, it is likely to be impossible to mitigate all side-channel attacks, but we certainly will attempt to do so where possible, as part of our aim to make Enarx Keeps as secure as possible.
TEE vs TPM #
You could implement many of the capabilities of a TPM within a TEE, but it doesn't make sense to create a "full" TPM implementation within a TEE on two levels:
- One of the key points of a TPM is that it's linked to the hardware, meaning that the boot sequence can be tied into PCRs (Platform Configuration Registers). TEEs aren't necessarily suitable as Hardware-Based Roots of Trust.
- Enarx provides a general processing environment. The capabilities of a TPM are carefully scoped, and to meet the requirements of the TCG (Trusted Computing Group, the standards body for TPMs), you need to implement these very carefully.
TEE vs HSM #
HSM's provide higher levels of protection than TEEs, but are separate modules, accessed via PCI bus, network, etc. TEEs are integral to the CPU packages on a motherboard. Both HSMs and TEE instances can be used as general-function processing units (depending on the model), and both can be programmed for particular uses (e.g. PKCS#11 modules). The cost of HSMs is high (typically thousands of dollars), whereas TEEs are integral to a chipset. The work to program an HSM is difficult.